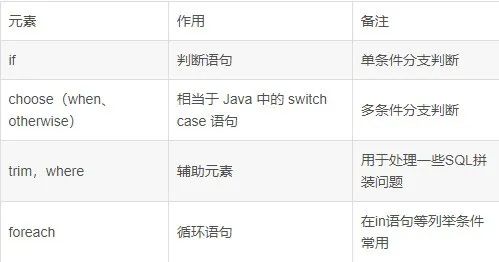
最近,有程序员用 SQL 重新翻译《出师表》,意外发现惊人契合度!原来治国平天下和写代码竟有这些共通逻辑……
先帝创业未半而中道崩殂
DELETE FROM `蜀国`
WHERE name = '刘玄德'AND `创业进度` < 0.5AND `存活状态` = true
今天下三分,益州疲弊
UPDATE `国家表`
SET `国力` = '疲弊'
WHERE `地区` = '益州' AND `分裂状态` = '三分天下';
侍卫之臣不懈于内,忠志之士忘身于外者
INSERT INTO `忠臣表` (`姓名`, `岗位`, `状态`)
VALUES
('侍中郭攸之', '宫内', '不懈工作'),
('将军向宠', '军营', '忘身作战');
诚宜开张圣听,以光先帝遗德
ALTER TABLE `皇帝表`
ADD COLUMN `圣听开启` BOOLEAN DEFAULT TRUE,
MODIFY COLUMN `继承遗志` VARCHAR(255) DEFAULT '光复汉室';
不宜妄自菲薄,引喻失义,以塞忠谏之路也
DELETE FROM `官员表`
WHERE `心理状态` = '妄自菲薄'
AND `言论记录` LIKE '%引喻失义%'
AND `谏言次数` < 1;
宫中府中,俱为一体,陟罚臧否,不宜异同
CREATE VIEW `统一考核视图` AS
SELECT * FROM `皇宫人员表`
UNION ALL
SELECT * FROM `丞相府人员表`
WITH CHECK OPTION `奖惩标准` = '公平一致';
亲贤臣,远小人
- 贤臣组
UPDATE `官员表`
SET `亲密度` = `亲密度` + 10
WHERE `品德评分` >= 90;
- 小人组
UPDATE `官员表`
SET `任职状态` = '流放'
WHERE `恶行记录` IS NOT NULL
AND `悔改状态` = FALSE;
先帝在时,每与臣论此事
SELECT `谈话内容`
FROM `先帝谈话记录`
INNER JOIN `诸葛亮工作日志`
ON `谈话时间` BETWEEN '建安十三年' AND '章武三年'
WHERE `议题分类` = '国家大事';
受命以来,夙夜忧叹
INSERT INTO `任务表` (`任务内容`, `负责人`, `状态`)
VALUES ('北定中原', '诸葛亮', '进行中')
ON DUPLICATE KEY UPDATE `最后进度` = NOW();
今南方已定,兵甲已足
UPDATE `军事部署表`
SET
`南部状态` = '已平定',
`装备库存` = 1000000
WHERE `年度` = YEAR(CURDATE());
当奖率三军,北定中原
CALL 发布军事任务('北伐中原', '诸葛亮', '赵云', '魏延');
此臣所以报先帝而忠陛下之职分也
CREATE TRIGGER `履行职责`
AFTER INSERT ON `皇帝诏令表`
FOR EACH ROW
BEGIN
UPDATE `大臣职责表`
SET `完成状态` = TRUE
WHERE `大臣ID` = 1; -- 诸葛亮ID
END;
愿陛下托臣以讨贼兴复之效
...